Table of Contents
Motivation
The development of the DistDir library started with the main goal to help model developers to integrate complex communication patterns in their scientific applications. The main use case in mind was the concurrent execution because it is crucial for exascale computing. It allows to scale an application beyond domain decomposition and to improve its efficiency because each component can run with the optimal number of processes and on the optimal hardware. The main challenge of concurrent execution is the computation of the communication patterns between different components and DistDir aims to target this issue with a clear interface and a minimal integration effort from model developers.
The API requires the user to provide only local information belonging to each MPI process, hiding the communication complexity. Once the communication algorithm is computed, also the actual exchange of messages is hidden and the user needs to provide pointers to data fields.
Design
The modular design of the library allows to expand it in the future by adding new algorithms or by adding support for new architectures. The library can be divided into a core and an exchanger component.
The core is where the distributed directory algorithm is implemented, but other algorithms can be easily added in the future. This part of the library will always run on CPU and it should always be used during the initialization of a model. It is the most computationally expensive part where the communication patterns are computed and its performance is crucial to scale the models.
The exchanger is where the actual data are exchanged using previously computed communication patterns. This component is designed with two levels of modularity. The higher level implements different exchanger types which are described in details in the Exchanger methods section of the Advance Topics page. The lower level supports different architectures for each exchanger type. These two levels of modularity can easily be configured by the user independently and for each exchanger object. This part of the library is usually called during the time loop of an application, thus the API functions are called many times during a simulation. The idea is to minimize the amount of memory allocated and deallocated during each function call and any additional setup in order to minimize overheads.
Algorithm
The library backend currently supports a simple implementation of a distributed directory algorithm which uses a third domain decomposition based on 1D buckets (rendevous decomposition) to compute the communication patterns. The main benefit of this algorithm is that it does not require global information to be sent to each MPI process and it can scale because each MPI process tsakes part in the rendevous decomposition. In the future it might be possible to involve a subset of processes in the rendevous decomposition which might be beneficial when a very high number of processes is involved in the communication.
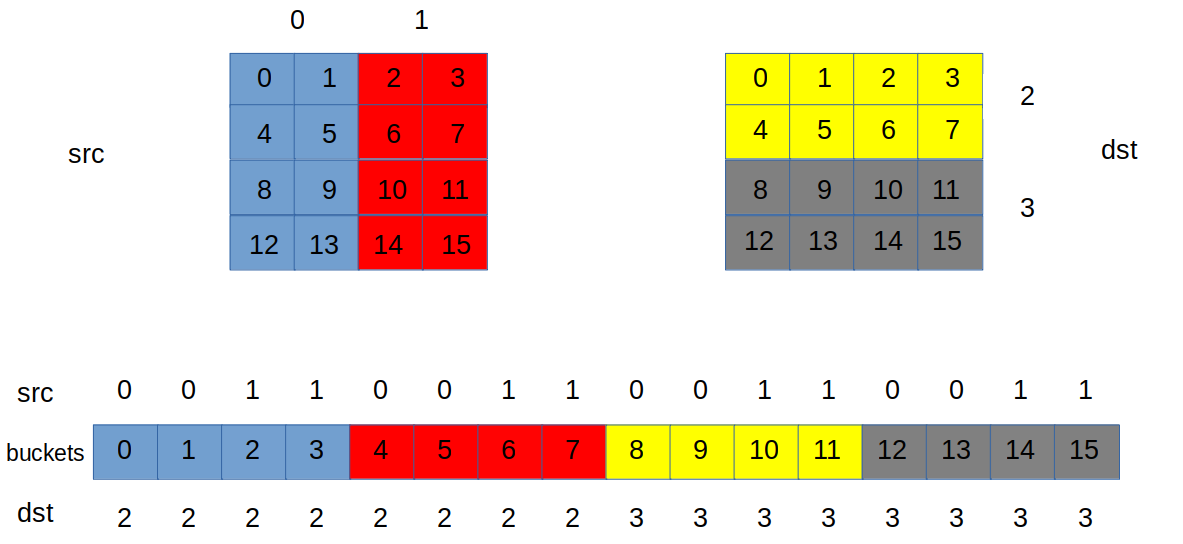
The algorithm is described using the figure below which shows a simple use case with one group of processes sending data to another group of processes. The two groups have different domain decompositions. The algorithm can be divided in two steps.
- Each process sends its rank information for each index of the process subdomain to the bucket where the index belongs.
- After the first step, each bucket has information about source and destination ranks for each index of the bucket. As a second step, each bucket sends information of source ranks to the destination ranks associated with the indices and vice versa.
After these two steps, each sending process has information about the destination ranks of its local index list and each receiving process has informatioin about source ranks of its local index list. This means that each MPI process has all the information to perform the actual exchange (communication patterns).